React 渲染行为(几乎)完整指南
关于 React 渲染行为的详细说明,以及 Context 和 React-Redux 如何影响渲染
我看到很多人对于 React 何时、为何以及如何重新渲染组件,以及使用 Context 和 React-Redux 如何影响这些重新渲染的时机和范围感到困惑。在反复解释这些内容数十次之后,我觉得有必要写一篇完整的说明,以便将来可以引导人们参考。请注意,所有这些信息在网上都已经有了,也已经在许多其他优秀的博客文章中做了解释,我在文末的"延伸阅读"部分链接了其中一些作为参考。但是,大家似乎很难将这些零散的知识拼凑在一起形成完整的理解,所以希望这篇文章能帮助一些人理清思路。
注意:2022 年 10 月更新,涵盖 React 18 和未来的 React 更新
我也在 React Advanced 2022 上做了一个基于这篇文章的演讲:
React Advanced 2022 - React 渲染行为(简要)指南
目录
什么是"渲染"?
渲染(Rendering) 是 React 要求你的组件根据当前的 props 和 state 组合来描述它们希望 UI 对应部分现在看起来是什么样子的过程。
渲染流程概述
在渲染过程中,React 会从组件树的根节点开始,向下遍历找到所有被标记为需要更新的组件。对于每个被标记的组件,React 会调用 FunctionComponent(props)(对于函数组件)或 classComponentInstance.render()(对于类组件),并保存渲染输出以供渲染过程的后续步骤使用。
组件的渲染输出通常使用 JSX 语法编写,然后在 JS 编译和准备部署时被转换为 React.createElement() 调用。createElement 返回 React 元素,这些是描述 UI 预期结构的普通 JS 对象。示例:
// 这个 JSX 语法:
return <MyComponent a={42} b="testing">Text here</MyComponent>
// 被转换为这个调用:
return React.createElement(MyComponent, {a: 42, b: "testing"}, "Text Here")
// 然后变成这个元素对象:
{type: MyComponent, props: {a: 42, b: "testing"}, children: ["Text Here"]}
// 而在内部,React 调用实际的函数来渲染它:
let elements = MyComponent({...props, children})
// 对于"宿主组件"如 HTML:
return <button onClick={() => {}}>Click Me</button>
// 变成
React.createElement("button", {onClick}, "Click Me")
// 最终:
{type: "button", props: {onClick}, children: ["Click me"]}在收集了整个组件树的渲染输出之后,React 会对新的对象树(通常被称为"虚拟 DOM")进行 diff 运算,并收集所有需要应用的更改列表,以使真实 DOM 与当前期望的输出一致。这个 diff 和计算过程被称为"协调(reconciliation)"。
然后 React 会在一个同步序列中将所有计算出的更改应用到 DOM 上。
注意: React 团队近年来已经淡化了"虚拟 DOM"这个术语。Dan Abramov 说过:
我希望我们能弃用"虚拟 DOM"这个术语。它在 2013 年有意义,因为否则人们会以为 React 在每次渲染时都创建 DOM 节点。但现在人们很少这样假设了。"虚拟 DOM"听起来像是对某些 DOM 问题的变通方案。但那不是 React 的本质。
React 是"值 UI"。它的核心原则是 UI 是一个值,就像字符串或数组一样。你可以将它保存在变量中、传递它、使用 JavaScript 控制流来处理它等等。这种表达能力才是重点——而不是某种避免对 DOM 应用更改的 diff 机制。
它甚至不总是代表 DOM,例如<Message recipientId={10} />不是 DOM。从概念上讲,它代表惰性函数调用:Message.bind(null, { recipientId: 10 })。
Render 阶段和 Commit 阶段
React 团队从概念上将这些工作分为两个阶段:
- "Render 阶段"包含渲染组件和计算变更的所有工作
- "Commit 阶段"是将这些变更应用到 DOM 的过程
在 commit 阶段 React 更新完 DOM 之后,它会相应地更新所有 ref 以指向请求的 DOM 节点和组件实例。然后同步运行类组件的 componentDidMount 和 componentDidUpdate 生命周期方法,以及 useLayoutEffect hooks。
然后 React 设置一个短暂的定时器,当它到期时,运行所有的 useEffect hooks。这一步也被称为"被动效果(Passive Effects)"阶段。
React 18 添加了"并发渲染(Concurrent Rendering)"特性,如 useTransition。这使 React 能够暂停 render 阶段的工作,让浏览器处理事件。React 会在适当的时候恢复、丢弃或重新计算该工作。一旦渲染过程完成,React 仍然会在一步中同步运行 commit 阶段。
理解这一点很关键:"渲染"和"更新 DOM"不是同一回事,组件可能被渲染但结果不产生任何可见变化。当 React 渲染一个组件时:
- 该组件可能返回与上次相同的渲染输出,因此不需要任何更改
- 在并发渲染中,React 可能最终会多次渲染一个组件,但如果其他更新使当前正在进行的工作失效,则每次都丢弃渲染输出
这个优秀的交互式 React hooks 时间线图有助于说明渲染、提交和执行 hooks 的顺序:
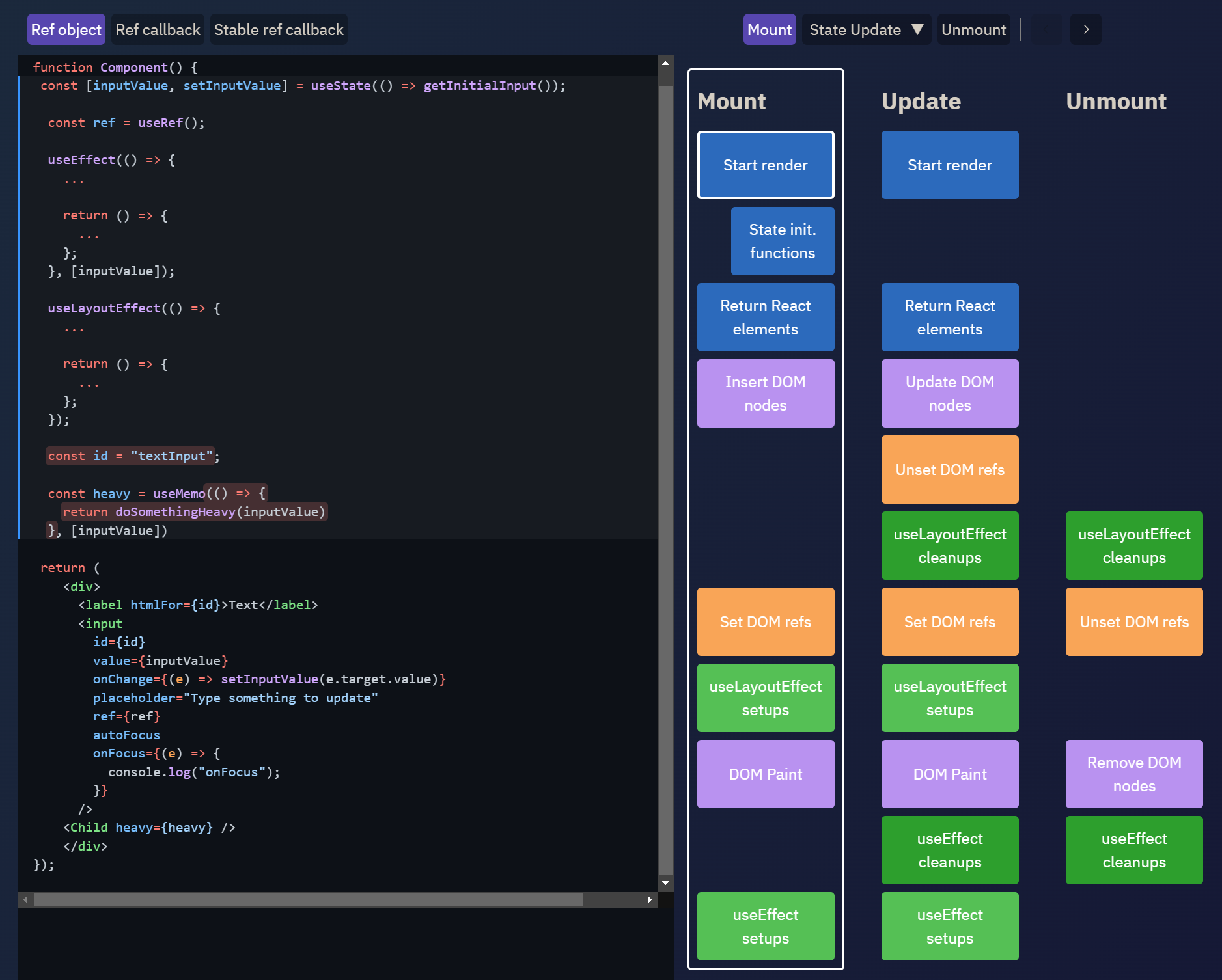
更多可视化资源参见:
React 如何处理渲染?
队列渲染
在初始渲染完成后,有几种不同的方式可以告诉 React 将重新渲染加入队列:
- 函数组件:
useState的 setter 函数useReducer的 dispatch
- 类组件:
this.setState()this.forceUpdate()
- 其他:
- 再次调用 ReactDOM 顶层的
render(<App>)方法(相当于对根组件调用forceUpdate())- 由新的
useSyncExternalStorehook 触发的更新
- 由新的
- 再次调用 ReactDOM 顶层的
注意,函数组件没有 forceUpdate 方法,但你可以通过使用一个始终递增计数器的 useReducer hook 来获得相同的行为:
const [, forceRender] = useReducer((c) => c + 1, 0);标准渲染行为
记住这一点非常重要:
React 的默认行为是当父组件渲染时,React 会递归渲染其内部的所有子组件!
举个例子,假设我们有一个组件树 A > B > C > D,并且已经将它们显示在页面上。用户点击了 B 中的一个按钮来递增计数器:
- 我们在
B中调用setState(),这会将 B 的重新渲染加入队列。 - React 从树的顶部开始渲染过程
- React 发现
A没有被标记为需要更新,跳过它 - React 发现
B被标记为需要更新,渲染它。B像上次一样返回<C />。 C本来没有被标记为需要更新。但是,因为它的父组件B渲染了,React 现在向下移动并渲染C。C 再次返回<D />。D也没有被标记为需要渲染,但由于其父组件C渲染了,React 向下移动并渲染D。
换一种方式重申:
渲染一个组件将默认导致其内部的所有组件也被渲染!
还有另一个关键点:
在正常渲染中,React 不关心"props 是否改变了"——它会无条件地渲染子组件,仅仅因为父组件渲染了!
这意味着在你的根 <App> 组件中调用 setState(),在没有其他改变行为的情况下,将会导致 React 重新渲染组件树中的每一个组件。毕竟,React 最初的一个卖点就是"表现得像我们在每次更新时重绘整个应用"。
现在,树中的大多数组件很可能会返回与上次完全相同的渲染输出,因此 React 不需要对 DOM 做任何更改。但是,React 仍然必须完成要求组件渲染自身并对渲染输出进行 diff 的工作。这两者都需要时间和精力。
记住,渲染不是一件坏事——它是 React 了解是否需要实际对 DOM 做任何更改的方式!
React 渲染的规则
React 渲染的一个主要规则是渲染必须是"纯的"且没有任何副作用!
这可能很棘手和令人困惑,因为许多副作用并不明显,也不会导致任何问题。例如,严格来说 console.log() 语句是一个副作用,但它实际上不会破坏任何东西。修改 prop 绝对是一个副作用,可能不会破坏任何东西。在渲染过程中发起 AJAX 请求也绝对是一个副作用,并且根据请求类型的不同,肯定会导致意想不到的应用行为。
Sebastian Markbage 写了一份名为The Rules of React的优秀文档。在其中,他定义了不同 React 生命周期方法(包括 render)的预期行为,以及哪些操作可以被认为是安全的"纯"操作,哪些是不安全的。值得完整阅读那份文档,但我在这里总结关键点:
- 渲染逻辑不得:
- 不能修改已有的变量和对象
- 不能创建随机值如
Math.random()或Date.now() - 不能发起网络请求
- 不能将 state 更新加入队列
- 不能创建随机值如
- 不能修改已有的变量和对象
- 渲染逻辑可以:
- 修改在渲染期间新创建的对象
- 抛出错误
- "延迟初始化"尚未创建的数据,如缓存值
- 修改在渲染期间新创建的对象
组件元数据和 Fibers
React 存储了一个内部数据结构,用于跟踪应用中当前存在的所有组件实例。这个数据结构的核心部分是一个名为"fiber"的对象,它包含描述以下信息的元数据字段:
- 在组件树的这个位置应该渲染什么组件类型
- 与该组件关联的当前 props 和 state
- 指向父组件、兄弟组件和子组件的指针
- React 用来跟踪渲染过程的其他内部元数据
如果你曾经听说过"React Fiber"这个短语被用来描述 React 的版本或特性,那实际上是指 React 内部的重写,将渲染逻辑切换为依赖这些"Fiber"对象作为关键数据结构。那是在 React 16.0 中发布的,所以此后的每个 React 版本都使用了这种方式。
Fiber 类型的简化版本如下:
export type Fiber = {
// 标识 fiber 类型的标签。
tag: WorkTag;
// 此子节点的唯一标识符。
key: null | string;
// 与此 fiber 关联的已解析函数/类。
type: any;
// 单链表树结构。
child: Fiber | null;
sibling: Fiber | null;
index: number;
// 输入是进入此 fiber 的数据(参数/props)
pendingProps: any;
memoizedProps: any; // 用于创建输出的 props。
// state 更新和回调的队列。
updateQueue: Array<State | StateUpdaters>;
// 用于创建输出的 state
memoizedState: any;
// 此 fiber 的依赖项(contexts、events),如果有的话
dependencies: Dependencies | null;
};(你可以在这里查看 React 18 中 Fiber 类型的完整定义。)
在渲染过程中,React 会遍历这棵 fiber 对象树,并在计算新的渲染结果时构建一棵更新的树。
注意,这些"fiber"对象存储了真实的组件 props 和 state 值。当你在组件中使用 props 和 state 时,React 实际上是在给你访问存储在 fiber 对象上的值。事实上,对于类组件,React 在渲染前会显式地将 componentInstance.props = newProps 复制到组件上。所以,this.props 确实存在,但它之所以存在是因为 React 从其内部数据结构中复制了引用过来。从这个意义上说,组件某种程度上是 React fiber 对象的外观(facade)。
类似地,React hooks 之所以工作,是因为React 将组件的所有 hooks 存储为附加到该组件 fiber 对象上的链表。当 React 渲染一个函数组件时,它从 fiber 获取那个 hook 描述条目的链表,每次你调用另一个 hook 时,它返回存储在 hook 描述对象中的适当值(如 useReducer 的 state 和 dispatch 值)。
当父组件首次渲染给定的子组件时,React 创建一个 fiber 对象来跟踪该组件的"实例"。对于类组件,它字面上调用 const instance = new YourComponentType(props)并将实际的组件实例保存到 fiber 对象上。对于函数组件,React 只是将 YourComponentType(props) 作为函数调用。
组件类型和协调
如"协调"文档页面所述,React 试图在重新渲染期间保持高效,尽可能重用现有的组件树和 DOM 结构。如果你要求 React 在树的同一位置渲染相同类型的组件或 HTML 节点,React 会重用它并在适当时仅应用更新,而不是从头重新创建。这意味着只要你持续要求 React 在同一位置渲染该组件类型,React 就会保持组件实例存活。对于类组件,它确实使用你组件的同一个实际实例。函数组件没有类那样的真正"实例",但我们可以将 <MyFunctionComponent /> 视为一个"实例",意思是"这种类型的组件正在这里显示并保持存活"。
那么,React 如何知道输出何时以及如何实际发生了变化?
React 的渲染逻辑首先基于元素的 type 字段进行比较,使用 === 引用比较。如果某个位置的元素更改为不同的类型,比如从 <div> 变为 <span> 或从 <ComponentA> 变为 <ComponentB>,React 会通过假设整个树已更改来加速比较过程。因此,React 会销毁整个现有的组件树部分,包括所有 DOM 节点,并从头重新创建。
这意味着**你绝不能在渲染时创建新的组件类型!**每当你创建一个新的组件类型时,它是一个不同的引用,这将导致 React 反复销毁和重新创建子组件树。
换句话说,不要这样做:
// ❌ 错误!
// 这每次都会创建一个新的 `ChildComponent` 引用!
function ParentComponent() {
function ChildComponent() {
return <div>Hi</div>;
}
return <ChildComponent />;
}相反,始终单独定义组件:
// ✅ 正确
// 这只创建一个组件类型引用
function ChildComponent() {
return <div>Hi</div>;
}
function ParentComponent() {
return <ChildComponent />;
}Keys 和协调
React 标识组件"实例"的另一种方式是通过 key 伪 prop。React 使用 key 作为唯一标识符,用来区分组件类型的特定实例。
注意,key 实际上不是一个真正的 prop——它是给 React 的指令。React 会始终将它剥离,它永远不会被传递给实际组件,所以你永远不能有 props.key——它始终是 undefined。
我们使用 keys 的主要场景是渲染列表。如果你渲染的数据可能以某种方式更改(如重新排序、添加或删除列表条目),那么 keys 在这里特别重要。特别重要的是,keys 应该尽可能使用数据中的某种唯一 ID——只在万不得已时才使用数组索引作为 keys!
// ✅ 使用数据对象的 ID 作为列表项的 key
todos.map((todo) => <TodoListItem key={todo.id} todo={todo} />);以下是一个说明为什么这很重要的例子。假设我渲染了一个包含 10 个 <TodoListItem> 组件的列表,使用数组索引作为 keys。React 看到 10 个项目,keys 为 0..9。现在,如果我们删除第 6 和第 7 项,并在末尾添加三个新条目,我们最终渲染的项目 keys 为 0..10。所以,对 React 来说,看起来我真的只是在末尾添加了一个新条目,因为我们从 10 个列表项变成了 11 个。React 会愉快地重用现有的 DOM 节点和组件实例。但是,这意味着我们现在可能在渲染 <TodoListItem key={6}> 时使用了之前传递给列表项 #8 的 todo 项。所以,组件实例仍然存活,但现在它得到了一个与之前不同的数据对象作为 prop。这可能有效,但也可能产生意想不到的行为。此外,React 现在必须去对几个列表项应用更新来更改文本和其他 DOM 内容,因为现有的列表项现在必须显示与之前不同的数据。这些更新在这里真的不应该是必要的,因为这些列表项都没有改变。
如果我们改为对每个列表项使用 key={todo.id},React 将正确地看到我们删除了两个项目并添加了三个新项目。它将销毁两个已删除的组件实例及其关联的 DOM,并创建三个新的组件实例及其 DOM。这比不必要地更新实际上没有改变的组件要好。
Keys 在列表之外也对组件实例标识很有用。你可以在任何时候向任何 React 组件添加 key 来标示其身份,更改该 key 将导致 React 销毁旧的组件实例和 DOM 并创建新的。一个常见的用例是列表 + 详情表单的组合,其中表单显示当前选中列表项的数据。渲染 <DetailForm key={selectedItem.id}> 将导致 React 在选中项更改时销毁并重新创建表单,从而避免表单内部陈旧 state 的问题。
渲染批处理和时机
默认情况下,每次调用 setState() 都会导致 React 启动一个新的渲染过程,同步执行它并返回。然而,React 也会自动应用一种优化,即渲染批处理。渲染批处理是指多次 setState() 调用只导致一个渲染过程被排入队列并执行,通常会有轻微的延迟。
React 社区通常将其描述为"state 更新可能是异步的"。新的 React 文档也将其描述为"State 是一个快照"。这指的就是这种渲染批处理行为。
在 React 17 及更早版本中,React 只在 React 事件处理器(如 onClick 回调)中进行批处理。在事件处理器之外排入队列的更新,如在 setTimeout 中、await 之后或在普通 JS 事件处理器中的更新,不会被合并批处理,而是每个都会导致单独的重新渲染。
然而,React 18 现在对在任何单个事件循环 tick 中排入队列的所有更新执行"自动批处理"。这有助于减少所需的总渲染次数。
让我们看一个具体的例子。
const [counter, setCounter] = useState(0);
const onClick = async () => {
setCounter(0);
setCounter(1);
const data = await fetchSomeData();
setCounter(2);
setCounter(3);
};在 React 17 中,这执行了三次渲染过程。第一次过程会将 setCounter(0) 和 setCounter(1) 批处理在一起,因为两者都发生在原始事件处理器调用栈期间,所以它们都发生在 unstable_batchedUpdates() 调用内部。
然而,对 setCounter(2) 的调用发生在 await 之后。这意味着原始的同步调用栈已经完成,函数的后半部分在一个完全独立的事件循环调用栈中很久之后才运行。因此,React 将在 setCounter(2) 调用内部作为最后一步同步执行整个渲染过程,完成渲染并从 setCounter(2) 返回。
然后 setCounter(3) 也会发生同样的事情,因为它也在原始事件处理器之外运行,因此也在批处理之外。
然而,在 React 18 中,这执行两次渲染过程。前两个 setCounter(0) 和 setCounter(1) 被批处理在一起,因为它们在同一个事件循环 tick 中。之后,在 await 之后,setCounter(2) 和 setCounter(3) 都被批处理在一起——即使它们在很久之后,那也是在同一个事件循环中排入队列的两个 state 更新,所以它们被批处理到第二次渲染中。
异步渲染、闭包和 State 快照
一个我们一直看到的极其常见的错误是,用户设置了一个新值,然后试图打印现有的变量名。然而,被打印的是原始值,而不是更新后的值。
function MyComponent() {
const [counter, setCounter] = useState(0);
const handleClick = () => {
setCounter(counter + 1);
// ❌ 这不会按预期工作!
console.log(counter);
// 打印的是原始值——为什么它还没有更新??????
};
}那么,为什么这不起作用?
如上所述,有经验的用户通常会说"React state 更新是异步的"。这某种程度上是对的,但比这更有细微差别,实际上这里有几个不同的问题在起作用。
严格来说,React 渲染实际上是同步的——它将在这个事件循环 tick 的最后以"微任务"的形式执行。(这确实有些吹毛求疵,但这篇文章的目标是精确的细节和清晰度。)然而,是的,从那个 handleClick 函数的角度来看,它是"异步的",因为你不能立即看到结果,实际更新发生在 setCounter() 调用很久之后。
然而,这不起作用有一个更大的原因。handleClick 函数是一个*"闭包"——它只能*看到在函数被定义时变量的值。换句话说,这些 state 变量是一个时间快照。
由于 handleClick 是在这个函数组件最近一次渲染期间定义的,它只能看到 counter 在那次渲染过程中的值。 当我们调用 setCounter() 时,它排入了一次未来的渲染过程,那次未来的渲染将有一个新的 counter 变量,具有新的值和一个新的 handleClick 函数...…但这个副本的 handleClick 永远不能看到那个新值。
新的 React 文档在State 作为快照部分更详细地介绍了这一点,强烈推荐阅读。
回到最初的例子:在你设置更新值之后立即尝试使用该变量几乎总是错误的做法,并且暗示你需要重新考虑如何使用该值。
渲染行为的边缘情况
Commit 阶段生命周期
在 commit 阶段的生命周期方法中有一些额外的边缘情况:componentDidMount、componentDidUpdate 和 useLayoutEffect。它们主要存在的目的是让你在渲染之后、浏览器绘制之前执行额外的逻辑。特别是,一个常见的用例是:
- 首次使用部分但不完整的数据渲染组件
- 在 commit 阶段的生命周期中,使用 refs 测量页面中实际 DOM 节点的真实尺寸
- 基于这些测量值在组件中设置一些 state
- 立即使用更新后的数据重新渲染
在这个用例中,我们根本不希望初始的"部分"渲染 UI 对用户可见——我们只想显示"最终"UI。浏览器会在 DOM 被修改时重新计算 DOM 结构,但在 JS 脚本仍在执行并阻塞事件循环时,它们实际上不会在屏幕上绘制任何东西。所以,你可以执行多次 DOM 修改,如 div.innerHTML = "a"; div.innerHTML = "b";,而 "a" 永远不会出现。
因此,React 将始终在 commit 阶段的生命周期中同步运行渲染。这样,如果你确实尝试执行像"部分->最终"切换这样的更新,屏幕上只会出现"最终"内容。
据我所知,useEffect 回调中的 state 更新会被排入队列,并在所有 useEffect 回调完成后的"被动效果"阶段结束时刷新。
协调器批处理方法
React 协调器(ReactDOM、React Native)有方法可以改变渲染批处理行为。
对于 React 17 及更早版本,你可以将事件处理器之外的多个更新包装在 unstable_batchedUpdates() 中以将它们批处理在一起。(注意,尽管有 unstable_ 前缀,它在 Facebook 的代码和公共库中被大量使用和依赖——React-Redux v7 在内部使用了 unstable_batchedUpdates)
由于 React 18 默认自动批处理,React 18 有一个 flushSync() API,你可以用它来强制立即渲染并选择退出自动批处理。
注意,由于这些是特定于协调器的 API,替代协调器如 react-three-fiber 和 ink 可能没有暴露它们。检查 API 声明或实现细节以了解有什么可用。
<StrictMode>
React 会在开发环境中对 <StrictMode> 标签内的组件进行双重渲染。这意味着你的渲染逻辑运行的次数与已提交的渲染过程次数不相同,你不能依赖渲染期间的 console.log() 语句来计算已发生的渲染次数。相反,要么使用 React DevTools Profiler 来捕获跟踪信息并计算已提交渲染的总数,要么在 useEffect hook 或 componentDidMount/Update 生命周期内添加日志。这样日志只会在 React 实际完成渲染过程并提交时打印。
在渲染期间设置 State
在正常情况下,你永远不应该在实际渲染逻辑中排入 state 更新。换句话说,创建一个在点击发生时调用 setSomeState() 的点击回调是可以的,但你不应该在实际渲染行为中调用 setSomeState()。
然而,有一个例外。函数组件可以在渲染期间直接调用 setSomeState(),只要是有条件地进行的,并且不会在这个组件每次渲染时都执行。这相当于类组件中 getDerivedStateFromProps 的函数组件等价物。如果函数组件在渲染期间排入了 state 更新,React 会立即应用 state 更新并同步重新渲染该单个组件,然后继续前进。如果组件无限地持续排入 state 更新并强制 React 重新渲染它,React 会在设定的重试次数后打断循环并抛出错误(目前是 50 次尝试)。这个技术可以用来立即根据 prop 更改强制更新 state 值,而不需要重新渲染 + 在 useEffect 内调用 setSomeState()。
提升渲染性能
虽然渲染是 React 工作方式中正常的预期部分,但渲染工作有时也确实可能是"浪费的"。如果一个组件的渲染输出没有改变,DOM 的那部分不需要更新,那么渲染该组件的工作确实有点浪费时间。
React 组件的渲染输出应该始终完全基于当前的 props 和当前的组件 state。因此,如果我们提前知道组件的 props 和 state 没有改变,我们应该也知道渲染输出是相同的,该组件不需要任何更改,我们可以安全地跳过渲染它的工作。
在尝试提升软件性能时,有两种基本方法:1) 更快地完成相同的工作,2) 做更少的工作。优化 React 渲染主要是通过在适当的时候跳过组件的渲染来减少工作量。
组件渲染优化技术
React 提供了三个主要 API,允许我们潜在地跳过组件的渲染:
主要方法是 React.memo(),一个内置的"高阶组件"类型。它接受你自己的组件类型作为参数,并返回一个新的包装组件。包装组件的默认行为是检查是否有任何 props 发生了变化,如果没有,则阻止重新渲染。函数组件和类组件都可以使用 React.memo() 来包装。(可以传入自定义的比较回调,但它实际上只能比较旧的和新的 props,所以自定义比较回调的主要用例是只比较特定的 props 字段而不是全部。)
其他选项是:
React.Component.shouldComponentUpdate:一个可选的类组件生命周期方法,会在渲染过程的早期被调用。如果它返回false,React 将跳过渲染该组件。它可以包含你想用来计算布尔结果的任何逻辑,但最常见的方法是检查组件的 props 和 state 自上次以来是否发生了变化,如果没有改变则返回false。React.PureComponent:由于 props 和 state 的比较是实现shouldComponentUpdate最常见的方式,PureComponent基类默认实现了该行为,可以替代Component+shouldComponentUpdate使用。
所有这些方法都使用一种称为**"浅比较(shallow equality)"**的比较技术。这意味着检查两个不同对象中的每个单独字段,看看对象的任何内容是否是不同的值。换句话说,obj1.a === obj2.a && obj1.b === obj2.b && ........。这通常是一个快速的过程,因为 === 比较对 JS 引擎来说非常简单。所以,这三种方法做的等价于 const shouldRender = !shallowEqual(newProps, prevProps)。
还有一个不太知名的技术:如果一个 React 组件在其渲染输出中返回与上次完全相同的元素引用,React 将跳过重新渲染该特定子组件。 至少有几种方式可以实现这个技术:
- 如果你在输出中包含
props.children,那么当这个组件进行 state 更新时该元素是相同的 - 如果你用
useMemo()包装一些元素,那些元素在依赖项改变之前会保持不变
示例:
// 如果我们更新 state,`props.children` 内容不会重新渲染
function SomeProvider({ children }) {
const [counter, setCounter] = useState(0);
return (
<div>
<button onClick={() => setCounter(counter + 1)}>Count: {counter}</button>
<OtherChildComponent />
{children}
</div>
);
}
function OptimizedParent() {
const [counter1, setCounter1] = useState(0);
const [counter2, setCounter2] = useState(0);
const memoizedElement = useMemo(() => {
// 如果 counter2 更新了,这个元素保持相同的引用,
// 所以除非 counter1 改变,否则它不会重新渲染
return <ExpensiveChildComponent />;
}, [counter1]);
return (
<div>
<button onClick={() => setCounter1(counter1 + 1)}>
Counter 1: {counter1}
</button>
<button onClick={() => setCounter1(counter2 + 1)}>
Counter 2: {counter2}
</button>
{memoizedElement}
</div>
);
}从概念上讲,我们可以说这两种方法的区别是:
React.memo():由子组件控制- 相同元素引用:由父组件控制
对于所有这些技术,跳过渲染一个组件意味着 React 也将跳过渲染整个子树,因为它实际上是立了一个停止标志来阻止默认的"递归渲染子组件"行为。
新的 props 引用如何影响渲染优化
我们已经看到默认情况下,React 会重新渲染所有嵌套组件,即使它们的 props 没有改变。这也意味着传递新引用作为 props 给子组件并不重要,因为无论你是否传递相同的 props,它都会渲染。所以,像这样是完全没问题的:
function ParentComponent() {
const onClick = () => {
console.log('Button clicked');
};
const data = { a: 1, b: 2 };
return <NormalChildComponent onClick={onClick} data={data} />;
}每次 ParentComponent 渲染时,它都会创建一个新的 onClick 函数引用和一个新的 data 对象引用,然后将它们作为 props 传递给 NormalChildComponent。(注意,不管我们是使用 function 关键字还是箭头函数来定义 onClick 都无所谓——它无论如何都是一个新的函数引用。)
这也意味着没有必要通过将"宿主组件"如 <div> 或 <button> 包装在 React.memo() 中来尝试优化渲染。那些基础组件下面没有子组件,所以渲染过程无论如何都会在那里停止。
然而,如果子组件试图通过检查 props 是否改变来优化渲染,那么传递新引用作为 props 将导致子组件渲染。如果新的 prop 引用确实是新数据,这很好。但是,如果父组件只是传递一个回调函数呢?
const MemoizedChildComponent = React.memo(ChildComponent);
function ParentComponent() {
const onClick = () => {
console.log('Button clicked');
};
const data = { a: 1, b: 2 };
return <MemoizedChildComponent onClick={onClick} data={data} />;
}现在,每次 ParentComponent 渲染时,这些新引用都将导致 MemoizedChildComponent 看到其 props 值已更改为新引用,它将继续重新渲染……即使 onClick 函数和 data 对象应该每次基本上是相同的东西!
这意味着:
MemoizedChildComponent将始终重新渲染,即使我们希望大多数时候跳过渲染- 它比较旧的和新的 props 所做的工作是浪费的
类似地,注意渲染 <MemoizedChild><OtherComponent /></MemoizedChild> 也会强制子组件始终渲染,因为 props.children 始终是一个新引用。
优化 props 引用
类组件不太需要担心意外创建新的回调函数引用,因为它们可以有始终是相同引用的实例方法。然而,它们可能需要为单独的子列表项生成唯一的回调,或者在匿名函数中捕获一个值并将其传递给子组件。这些都会产生新引用,在渲染时创建新对象作为子 props 也是如此。React 没有内置任何东西来帮助优化这些情况。
对于函数组件,React 提供了两个 hooks 来帮助你重用相同的引用:useMemo 用于任何类型的通用数据(如创建对象或进行复杂计算),useCallback 专门用于创建回调函数。
是否应该缓存一切?
如上所述,你不需要对传递给子组件的每一个函数或对象都使用 useMemo 和 useCallback——只有在它会对子组件的行为产生差异时才需要。(话虽如此,useEffect 的依赖数组比较确实添加了另一个用例,即子组件可能希望接收一致的 props 引用,这确实使事情更加复杂。)
另一个经常出现的问题是"为什么 React 不默认将所有东西包装在 React.memo() 中?"
Dan Abramov 反复指出,memoization 仍然会产生比较 props 的成本,并且在许多情况下,memoization 检查永远无法阻止重新渲染,因为组件总是接收新的 props。例如,看看 Dan 的这个 Twitter 帖子:
为什么 React 不默认在每个组件周围放置 memo()?那不是更快吗?我们应该做一个基准测试来检查吗?
问问你自己:
你为什么不在每个函数周围放置 Lodash memoize()?那不会让所有函数更快吗?我们需要基准测试吗?为什么不需要?
另外,虽然我没有具体的链接,但默认对所有组件尝试应用这一点可能会因为人们修改数据而不是以不可变方式更新数据的情况而导致 bug。
我曾在 Twitter 上与 Dan 公开讨论过这个问题。我个人认为,广泛使用 React.memo() 可能会是应用整体渲染性能的净收益。正如我在去年的一个扩展 Twitter 帖子中所说:
React 社区总体上似乎对"性能"过度关注,然而大部分讨论都围绕着通过 Medium 帖子和 Twitter 评论传递下来的过时的"部落智慧",而不是基于具体的使用情况。
关于"渲染"和性能影响的概念确实存在集体误解。是的,React 完全基于渲染——必须渲染才能做任何事情。不,大多数渲染开销并不大。
"浪费的"重新渲染当然不是世界末日。从根节点重新渲染整个应用也不是。话虽如此,一个没有 DOM 更新的"浪费的"重新渲染确实是不需要消耗的 CPU 周期。这对大多数应用来说是问题吗?可能不是。它可以改善吗?可能可以。
是否有些应用默认的"全部重新渲染"方法不够用?当然有,这就是 sCU、PureComponent 和 memo() 存在的原因。
用户应该默认将所有东西包装在 memo() 中吗?可能不应该,如果只是因为你应该思考你应用的性能需求的话。如果你这样做了会真正造成伤害吗?不会,实际上我预期它确实有净收益(尽管 Dan 关于浪费比较的观点)
基准测试是有缺陷的,结果根据场景和应用高度可变吗?当然。话虽如此,如果人们能开始指向硬数字来进行这些讨论,而不是玩"我曾看到一个评论……"的传话游戏,那将非常非常有帮助
我很想看到 React 团队和更大社区的一堆基准测试套件来测量一堆场景,这样我们就可以一劳永逸地停止争论大部分这些东西。函数创建、渲染成本、优化……请给出具体证据!
Dan 的标准答案是应用结构和更新模式差异很大,所以很难做出有代表性的基准测试。
我仍然认为一些实际数字对讨论是有用的
在 React issues 中还有一个关于"什么时候不应该使用 React.memo?"的扩展讨论。
注意**新的 React 文档专门解答了"缓存一切?"的问题**:
使用
memo进行优化只在你的组件经常使用完全相同的 props 重新渲染、且其重新渲染逻辑很昂贵时才有价值。如果你的组件重新渲染时没有明显的卡顿,memo是不必要的。请记住,如果传递给组件的 props 总是不同的(例如你传递了在渲染期间定义的对象或普通函数),memo是完全没用的。这就是为什么你通常需要将useMemo和useCallback与memo一起使用。在其他情况下包装
memo没有好处。这样做也没有什么明显的坏处,所以一些团队选择不考虑单个情况,尽可能多地进行 memoize。这种方法的缺点是代码变得不太可读。此外,并非所有 memoization 都有效:一个"总是新的"值就足以破坏整个组件的 memoization。
请参阅该链接下的详细部分,以获取关于避免不必要 memoization 和提升性能的进一步建议。
不可变性与重新渲染
React 中的 State 更新应该始终以不可变方式完成。主要有两个原因:
- 根据你修改的内容和位置,可能导致组件在你期望它们渲染时没有渲染
- 它会导致对数据实际何时以及为何被更新的困惑
让我们看几个具体的例子。
正如我们所见,React.memo / PureComponent / shouldComponentUpdate 都依赖于当前 props 与先前 props 的浅比较。所以,预期是我们可以通过 props.someValue !== prevProps.someValue 来知道一个 prop 是否是新值。
如果你进行了修改(mutation),那么 someValue 是相同的引用,这些组件将假设什么都没有改变。
注意,这具体是在我们尝试通过避免不必要的重新渲染来优化性能的时候。如果 props 没有改变,重新渲染是"不必要的"或"浪费的"。如果你修改了数据,组件可能会错误地认为什么都没有改变,然后你会纳闷为什么组件没有重新渲染。
另一个问题是 useState 和 useReducer hooks。每次我调用 setCounter() 或 dispatch() 时,React 都会排入一次重新渲染。然而,React 要求任何 hook state 更新必须传入/返回一个新引用作为新的 state 值,无论是新的对象/数组引用,还是新的原始值(字符串/数字等)。
React 在 render 阶段应用所有 state 更新。当 React 尝试应用来自 hook 的 state 更新时,它会检查新值是否是相同的引用。React 将始终完成排入更新的组件的渲染。然而,如果值是与之前相同的引用,并且没有其他继续渲染的理由(如父组件已渲染),那么 React 将丢弃该组件的渲染结果并完全退出渲染过程。所以,如果我像这样修改一个数组:
const [todos, setTodos] = useState(someTodosArray);
const onClick = () => {
todos[3].completed = true;
setTodos(todos);
};那么组件将无法重新渲染。
(注意,React 确实有一个"快速路径"退出机制,在某些情况下会在排入 state 更新之前尝试检查新值。由于这也依赖于直接引用检查,这是需要进行不可变更新的另一个例子。)
从技术上讲,只有最外层的引用必须以不可变方式更新。如果我们将那个例子改为:
const onClick = () => {
const newTodos = todos.slice();
newTodos[3].completed = true;
setTodos(newTodos);
};那么我们创建了一个新的数组引用并传入了它,组件将会重新渲染。
注意,类组件的 this.setState() 和函数组件的 useState 及 useReducer hooks 在处理修改和重新渲染方面有明显的行为差异。this.setState() 根本不在乎你是否进行了修改——它总是完成重新渲染。所以,这会重新渲染:
const { todos } = this.state;
todos[3].completed = true;
this.setState({ todos });实际上,传入一个空对象如 this.setState({}) 也会重新渲染。
除了所有实际的渲染行为之外,修改还会给标准的 React 单向数据流带来困惑。修改可能导致其他代码看到不同的值,而预期是它们根本没有改变。这使得更难知道某个 state 何时以及为何实际上应该被更新,或者更改来自哪里。
底线:React 和 React 生态系统的其他部分都假设不可变更新。任何时候你进行修改,都有产生 bug 的风险。不要这样做。
测量 React 组件渲染性能
使用 React DevTools Profiler 来查看哪些组件在每次 commit 中渲染了。找到意外渲染的组件,使用 DevTools 找出为什么它们渲染了,然后修复问题(也许通过用 React.memo() 包装它们,或者让父组件缓存它传递下去的 props)。
另外,记住 React 在开发构建中运行得慢得多。你可以在开发模式下分析你的应用来查看哪些组件在渲染以及为什么,并对组件之间的相对渲染时间进行比较("在这次 commit 中,组件 B 的渲染时间是组件 A 的 3 倍")。但是,永远不要使用 React 开发构建来测量绝对渲染时间——只使用生产构建来测量绝对时间!(否则 Dan Abramov 将不得不来训斥你使用不准确的数字)。注意,如果你想实际使用 profiler 从类似生产的构建中捕获时间数据,你需要使用React 的特殊"profiling"构建。
Context 与渲染行为
React 的 Context API 是一种使单个用户提供的值可用于组件子树的机制。给定 <MyContext.Provider> 内的任何组件都可以从该 context 实例中读取值,而无需通过每个中间组件显式地将该值作为 prop 传递。
Context 不是一个"状态管理"工具。你必须自己管理传入 context 的值。这通常通过将数据保存在 React 组件的 state 中,并根据该数据构造 context 值来完成。
Context 基础
一个 context provider 接收一个单独的 value prop,如 <MyContext.Provider value={42}>。子组件可以通过渲染 context consumer 组件并提供一个 render prop 来消费该 context,如:
<MyContext.Consumer>{ (value) => <div>{value}</div>}</MyContext.Consumer>
或者在函数组件中调用 useContext hook:
const value = useContext(MyContext)
更新 Context 值
React 检查当周围的组件渲染 provider 时,context provider 是否被赋予了新值。如果 provider 的值是一个新引用,那么 React 知道该值已更改,消费该 context 的组件需要被更新。
注意,传递一个新对象给 context provider 将会导致它更新:
function GrandchildComponent() {
const value = useContext(MyContext);
return <div>{value.a}</div>;
}
function ChildComponent() {
return <GrandchildComponent />;
}
function ParentComponent() {
const [a, setA] = useState(0);
const [b, setB] = useState('text');
const contextValue = { a, b };
return (
<MyContext.Provider value={contextValue}>
<ChildComponent />
</MyContext.Provider>
);
}在这个例子中,每次 ParentComponent 渲染时,React 会注意到 MyContext.Provider 被赋予了新值,并在继续向下遍历时寻找消费 MyContext 的组件。当 context provider 有新值时,每个消费该 context 的嵌套组件都将被强制重新渲染。
注意,从 React 的角度来看,每个 context provider 只有一个值——不管那是对象、数组还是原始值,它只是一个 context 值。目前,没有办法让消费 context 的组件跳过由新 context 值引起的更新,即使它只关心新值的一部分。
如果一个组件只需要 value.a,而更新导致了新的 value.b 引用……不可变更新和 context 渲染的规则要求 value 也必须是一个新引用,因此读取 value.a 的组件也会渲染。
State 更新、Context 和重新渲染
是时候将一些部分组合在一起了。我们知道:
- 调用
setState()会排入该组件的渲染 - React 默认递归渲染嵌套组件
- Context providers 由渲染它们的组件赋予值
- 该值通常来自该父组件的 state
这意味着默认情况下,渲染 context provider 的父组件的任何 state 更新都将导致其所有后代重新渲染,无论它们是否读取 context 值!。
如果我们回顾上面的 Parent/Child/Grandchild 示例,我们可以看到 GrandchildComponent 将会重新渲染,但不是因为 context 更新——它将重新渲染是因为 ChildComponent 渲染了! 在这个例子中,没有任何东西试图优化掉"不必要的"渲染,所以每当 ParentComponent 渲染时,React 默认渲染 ChildComponent 和 GrandchildComponent。如果父组件将新的 context 值放入 MyContext.Provider,GrandchildComponent 在渲染时会看到新值并使用它,但 context 更新并没有导致 GrandchildComponent 渲染——它本来就会发生。
Context 更新与渲染优化
让我们修改那个示例,使其实际上尝试进行优化,但我们会通过在底部添加一个 GreatGrandchildComponent 来增加一个变化:
function GreatGrandchildComponent() {
return <div>Hi</div>
}
function GrandchildComponent() {
const value = useContext(MyContext);
return (
<div>
{value.a}
<GreatGrandchildComponent />
</div>
}
function ChildComponent() {
return <GrandchildComponent />
}
const MemoizedChildComponent = React.memo(ChildComponent);
function ParentComponent() {
const [a, setA] = useState(0);
const [b, setB] = useState("text");
const contextValue = {a, b};
return (
<MyContext.Provider value={contextValue}>
<MemoizedChildComponent />
</MyContext.Provider>
)
}现在,如果我们调用 setA(42):
ParentComponent将渲染- 创建一个新的
contextValue引用 - React 看到
MyContext.Provider有新的 context 值,因此MyContext的任何消费者都需要被更新 - React 将尝试渲染
MemoizedChildComponent,但看到它被React.memo()包装了。根本没有传递任何 props,所以 props 实际上没有改变。React 将完全跳过渲染ChildComponent。 - 然而,
MyContext.Provider有更新,所以可能有更下层的组件需要知道这一点。 - React 继续向下并到达
GrandchildComponent。它看到MyContext被GrandchildComponent读取,因此由于有新的 context 值,它应该重新渲染。React 继续前进并重新渲染GrandchildComponent,具体是因为 context 的变化。 - 因为
GrandchildComponent确实渲染了,React 然后继续前进并渲染其内部的所有内容。所以,React 也会重新渲染GreatGrandchildComponent。
换句话说,正如 Sophie Alpert 所说:
你的 Context Provider 正下方的那个 React 组件可能应该使用
React.memo
这样,父组件中的 state 更新不会强制每个组件重新渲染,只有读取 context 的部分才会。(你也可以通过让 ParentComponent 渲染 <MyContext.Provider>{props.children}</MyContext.Provider> 来获得基本相同的结果,这利用了"相同元素引用"技术来避免子组件重新渲染,然后从上一级渲染 <ParentComponent><ChildComponent /></ParentComponent>。)
但是请注意,一旦 GrandchildComponent 基于下一个 context 值渲染了,React 就会直接回到其默认行为——递归重新渲染所有内容。所以,GreatGrandchildComponent 被渲染了,它下面的任何其他东西也会被渲染。
Context 和渲染器边界
通常,React 应用完全使用单个渲染器(如 ReactDOM 或 React Native)构建。但是,核心渲染和协调逻辑作为一个名为 react-reconciler 的包发布,你可以用它来构建自己的针对其他环境的 React 版本。好的例子有 react-three-fiber(使用 React 来驱动 Three.js 模型和 WebGL 渲染)和 ink(使用 React 绘制终端文本 UI)。
一个长期存在的限制是,如果你的应用中有多个渲染器(例如在 ReactDOM 中显示 React-Three-Fiber 内容),context providers 不会穿过渲染器边界。所以,如果组件树看起来是这样的:
function App() {
return (
<MyContext.Provider>
<DomComponent>
<ReactThreeFiberParent>
<ReactThreeFiberChild />
</ReactThreeFiberParent>
</DomComponent>
</MyContext.Provider>
);
}其中 ReactFiberParent 创建并显示使用 React-Three-Fiber 渲染的内容,那么 <ReactThreeFiberChild> 将无法看到 <MyContext.Provider> 的值。
这是 React 的一个已知限制,目前没有官方方法来解决。
话虽如此,React-Three-Fiber 背后的 Poimandres 组织已经有了一些使 context 桥接可行的内部 hack,他们最近发布了一个名为 https://github.com/pmndrs/its-fine 的库,其中包含一个 useContextBridge hook,这是一个有效的变通方案。
React-Redux 与渲染行为
各种形式的"CONTEXT 还是 REDUX?!?!??!"似乎是我目前在 React 社区中看到的被问得最多的问题。(这个问题本身就是一个伪命题,因为 Redux 和 Context 是做不同事情的不同工具。)
话虽如此,当这个话题出现时,人们反复指出的一点是"React-Redux 只重新渲染实际需要渲染的组件,所以它比 context 更好"。
这在某种程度上是对的,但答案比这更有细微差别。
React-Redux 订阅机制
我看到很多人重复"React-Redux 在内部使用 context"这句话。这在技术上也是对的,但 React-Redux 使用 context 来传递 Redux store 实例,而不是当前的 state 值。这意味着我们始终向 <ReactReduxContext.Provider> 传递相同的 context 值。
记住,Redux store 在每次 dispatch action 时都会运行其所有订阅者通知回调。需要使用 Redux 的 UI 层总是订阅 Redux store,在其订阅者回调中读取最新 state,diff 值,如果相关数据已更改则强制重新渲染。订阅回调过程完全在 React 之外发生,只有当 React-Redux 知道特定 React 组件所需的数据已更改(基于 mapState 或 useSelector 的返回值)时,React 才会参与进来。
这导致了与 context 非常不同的性能特征。是的,可能会有更少的组件始终在渲染,但是 React-Redux 将始终必须在每次 store state 更新时为整个组件树运行 mapState/useSelector 函数。大多数时候,运行这些 selectors 的成本小于 React 做另一次渲染过程的成本,所以通常是净收益,但这是必须完成的工作。然而,如果那些 selectors 进行昂贵的转换或意外返回新值,那可能会拖慢速度。
connect 和 useSelector 的区别
connect 是一个高阶组件。你传入自己的组件,connect 返回一个包装组件,该包装组件完成订阅 store、运行你的 mapState 和 mapDispatch、以及将组合后的 props 传递给你的组件的所有工作。
connect 包装组件始终表现得等同于 PureComponent/React.memo(),但侧重点略有不同:connect 只会在传递给你组件的组合 props 发生改变时才让你的组件渲染。通常,最终的组合 props 是 {...ownProps, ...stateProps, ...dispatchProps} 的组合,所以来自父组件的任何新 prop 引用确实会导致你的组件渲染,与 PureComponent 或 React.memo() 相同。除了父组件的 props 之外,mapState 返回的任何新引用也会导致你的组件渲染。(由于你可以自定义 ownProps/stateProps/dispatchProps 如何合并,也可以改变这种行为。)
另一方面,useSelector 是一个在你自己的函数组件内部调用的 hook。因此,useSelector 无法阻止你的组件在父组件渲染时渲染!
这是 connect 和 useSelector 之间的一个关键性能差异。使用 connect,每个连接的组件都表现得像 PureComponent,因此充当防火墙,防止 React 的默认渲染行为级联到整个组件树。由于典型的 React-Redux 应用有许多连接的组件,这意味着大多数重新渲染级联被限制在组件树的一个相当小的部分。React-Redux 将根据数据变化强制连接的组件渲染,它下面的 2-3 个组件可能也会渲染,然后 React 遇到另一个不需要更新的连接组件,那就停止了渲染级联。
此外,拥有更多连接的组件意味着每个组件可能从 store 中读取更小的数据片段,因此在任何给定的 action 之后不太可能需要重新渲染。
如果你只使用函数组件和 useSelector,那么与使用 connect 相比,基于 Redux store 更新,你的组件树中可能有更大部分会重新渲染,因为没有其他连接的组件来阻止那些渲染级联继续沿着树向下传播。
如果那成为性能问题,那么答案是根据需要自己将组件包装在 React.memo() 中,以防止由父组件引起的不必要重新渲染。
React 未来的改进
"React Forget" 自动缓存编译器
自从 React hooks 首次推出,我们开始处理 useEffect 和 useMemo 等 hooks 的依赖数组以来,React 团队就说过他们打算让 hooks 的 deps 数组成为"一个足够先进的编译器可以自动生成的东西"。换句话说,在 hook 中使用一个名为 counter 的变量,编译器会在构建时自动为你插入 [counter] 依赖数组。
尽管在多次讨论中出现,这个"足够先进的编译器"一直没有实现。社区尝试过创建自己的自动 memoization 方法,如 Babel 宏,但没有出现官方编译器……
直到 ReactConf 2021,React 团队做了一个题为"React Without Memo"的演讲。在那次演讲中,他们演示了一个代号为 "React Forget" 的实验性编译器。它旨在重写函数组件的主体以自动添加 memoization 能力。
React Forget 真正令人兴奋的是,它不仅尝试缓存 hook 依赖数组,它还缓存 JSX 元素返回值。由于我们从前面知道 React 有一个"相同元素引用"优化可以防止重新渲染子组件,这意味着 React Forget 可能有效地消除整个 React 组件树中的不必要渲染!
截至 2022 年 10 月,React Forget 编译器尚未发布,但从 React 团队传出的消息令人鼓舞。据说有 3-4 名工程师全职在构建它,目标是在公开发布供社区试用之前让 Facebook.com 完全运行起来。还有其他迹象表明工作进展顺利——useEvent RFC 基于"如果 React Forget 成功的话它可能不完全必要"的理由被关闭了,其他讨论也普遍暗示"如果由于自动 memoization 太多重新渲染的问题在未来消失了呢?"
所以,目前没有保证,但有理由对 React Forget 成功的机会保持乐观。
Context Selectors
我们之前说过 Context API 最大的弱点是组件不能选择性地订阅 context 值的一部分,因此所有读取该 context 的组件在值更新时都会重新渲染。
2019 年 7 月,一位社区成员撰写了一个提议"context selectors"API 的 RFC,允许组件选择性地只订阅 context 的一部分。那个 RFC 放了一段时间,最终出现了活动的迹象。Andrew Clark 随后在 2021 年 1 月在 React 中实现了 context selectors 的概念验证方法,新能力隐藏在内部特性标志后面用于实验。
遗憾的是,自那以后 context selectors 特性没有进一步的进展。从讨论和 PR 来看,概念验证版本几乎肯定需要对 API 设计进行更改和迭代才能最终确定。也有可能这可能是另一个如果 React Forget 编译器成功就会半过时的特性。
如果这个特性真的有一天发布了,它将使 Context + useReducer 组合成为处理大量 React 应用 state 的更可行选择。
值得注意的是,确实有一个来自 Daishi Kato(Zustand 和 Jotai 的维护者)的 useContextSelector 库,在此期间可能作为 polyfill 使用。
总结
- React 默认总是递归渲染组件,所以当父组件渲染时,其子组件也会渲染
- 渲染本身是正常的——它是 React 了解需要对 DOM 做什么更改的方式
- 但是,渲染需要时间,UI 输出没有变化的"浪费渲染"可能会累积
- 大多数时候传递新引用(如回调函数和对象)是可以的
React.memo()等 API 可以在 props 没有改变时跳过不必要的渲染- 但如果你总是传递新引用作为 props,
React.memo()永远无法跳过渲染,所以你可能需要缓存那些值 - Context 使值可以被任何感兴趣的深层嵌套组件访问
- Context providers 通过引用比较它们的值来判断是否改变
- 新的 context 值确实会强制所有嵌套的消费者重新渲染
- 但是,很多时候子组件本来就会因为正常的父->子渲染级联过程而重新渲染
- 所以你可能想要用
React.memo()包装 context provider 的子组件,或使用{props.children},这样在你更新 context 值时整个树不会一直渲染 - 当子组件基于新的 context 值渲染时,React 也会从那里继续级联渲染
- React-Redux 使用对 Redux store 的订阅来检查更新,而不是通过 context 传递 store state 值
- 这些订阅在每次 Redux store 更新时运行,所以它们需要尽可能快
- React-Redux 做了大量工作来确保只有数据发生变化的组件才被强制重新渲染
connect表现得像React.memo(),所以拥有很多连接的组件可以最小化同一时间渲染的组件总数useSelector是一个 hook,所以它无法阻止由父组件引起的渲染。一个到处只使用useSelector的应用可能应该给一些组件添加React.memo()来帮助避免渲染一直级联。- 如果 "React Forget" 自动缓存编译器确实发布了,可能会大大简化所有这些。
最终思考
显然,整个情况比"context 使一切渲染,Redux 不会,使用 Redux"要复杂得多。不要误解我,我希望人们使用 Redux,但我也希望人们清楚地理解不同工具所涉及的行为和权衡,以便他们能够为自己的用例做出明智的决定。
由于大家似乎总是问"什么时候应该使用 Context,什么时候应该使用 (React-)Redux?",让我继续回顾一些标准的经验法则:
- 使用 context 如果:
- 你只需要传递一些不经常改变的简单值
- 你有一些 state 或函数需要在应用的部分区域中访问,并且你不想一路将它们作为 props 传递下去
- 你想坚持使用 React 内置的东西,不添加额外的库
- 你只需要传递一些不经常改变的简单值
- 使用 (React-)Redux 如果:
- 你有大量的应用 state 在应用的许多地方需要
- 应用 state 随时间频繁更新
- 更新该 state 的逻辑可能很复杂
- 应用有中大型代码库,可能由许多人参与开发
- 你有大量的应用 state 在应用的许多地方需要
请注意,这些不是硬性的、排他的规则——它们只是关于这些工具何时可能有意义的一些建议性指导方针! 一如既往,请花一些时间自己决定什么是你正在处理的任何情况的最佳工具。
总的来说,希望这份解释能帮助人们理解在各种情况下 React 渲染行为实际发生了什么的全貌。
延伸阅读
我在 2022 年 10 月的 React Advanced 录制了这篇文章的会议演讲版本:
我最近看到了几篇专门介绍"React 渲染如何工作?"的好文章,我将推荐它们作为阅读材料:
- 推荐的 React 渲染文章:
除此之外,参见以下额外资源:
- 通用
- React 渲染行为
- React docs: Reconciliation
- React class lifecycle methods diagram
- React hooks lifecycle diagram
- React issues: bailing out of context and hooks
- React issues: why
setStateis async - Seb Markbage: "Context is good for low-frequency updates, not Flux-like state propagation"
- Ryan Florence: React, Inline Functions, and Performance
- James K Nelson: React context and performance
- Will It Render? A visualization for component rendering
- React docs: Reconciliation
- 优化渲染性能
- 分析 React 组件
- React-Redux 性能